
Data Parsing is a term that you often come across when you work with large quantities of data, especially for those who scrape data from the web as well as software engineers. However, data parsing is a topic that needs to be discussed in greater depth. For instance, what exactly is data parsing, and how
Parsowanie danych to termin, z którym często można się zetknąć podczas pracy z dużymi ilościami danych, szczególnie dla tych, którzy pobierają dane z sieci, a także dla inżynierów oprogramowania. Parsowanie danych jest jednak tematem, który wymaga szerszego omówienia. Na przykład, czym dokładnie jest parsowanie danych i jak zaimplementować je w prawdziwym świecie.
Ten artykuł odpowie na wszystkie powyższe pytania i zapewni przegląd istotnych terminologii związanych z analizowaniem danych.
Po wyodrębnieniu dużych ilości danych ze skrobania stron internetowych są one w formacie HTML. Niestety, nie jest to format czytelny dla osób niebędących programistami. Musisz więc wykonać dalszą pracę nad danymi, aby przekształcić je w format czytelny dla człowieka, dzięki czemu będzie on wygodny do analizy przez naukowców zajmujących się danymi. To właśnie parser wykonuje większość tej ciężkiej pracy podczas parsowania.
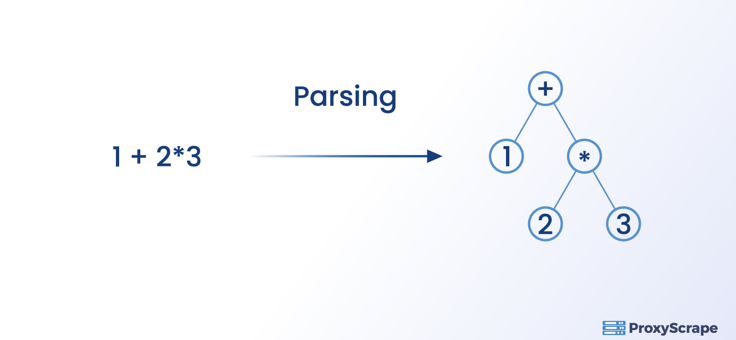
Parser konwertuje dane w jednym formacie na dane w innej formie. Na przykład parser przekonwertuje dane HTML uzyskane w wyniku scrapingu na JSON, CSV, a nawet tabelę, tak aby były w formacie, który można odczytać i przeanalizować. Warto również wspomnieć, że parser nie jest przywiązany do żadnego konkretnego formatu danych.
Parser nie analizuje każdego ciągu HTML, ponieważ dobry parser odróżni wymagane dane w znacznikach HTML od reszty.
Jak wspomniano w poprzedniej sekcji, ponieważ parser nie jest powiązany z jedną konkretną technologią, z natury jest wyjątkowo elastyczny. Dlatego korzysta z nich wiele różnych technologii:
Języki skryptowe - są to języki, które nie wymagają kompilatora do wykonania, ponieważ działają w oparciu o serię poleceń w pliku. Typowymi przykładami są PHP, Python i JavaScript.
Java i inne języki programowania - języki programowania wysokiego poziomu, takie jak Java, wykorzystują kompilator do konwersji kodu źródłowego na język asemblera. Parser jest istotnym elementem tych kompilatorów, który tworzy wewnętrzną reprezentację kodu źródłowego.
HTML i XML - w przypadku HTML parser wyodrębnia tekst w znacznikach HTML, takich jak tytuł, nagłówki, akapity itp. Natomiast parser XML to biblioteka, która ułatwia odczytywanie i manipulowanie dokumentami XML.
SQL i języki baz danych - na przykład parser SQL analizuje zapytanie SQL i generuje pola zdefiniowane w zapytaniu SQL.
Języki modelowania - parser w językach modelowania pozwala programistom, analitykom i interesariuszom zrozumieć strukturę modelowanego systemu.
Interaktywne języki danych - są wykorzystywane w interaktywnym przetwarzaniu dużych ilości danych, w tym w nauce o kosmosie i fizyce Słońca.
Głównym powodem potrzeby parsowania jest to, że różne podmioty potrzebują danych w różnych formatach. Parsowanie umożliwia zatem przekształcanie danych tak, aby człowiek lub, w niektórych przypadkach, oprogramowanie mogło je zrozumieć. Jednym z wybitnych przykładów tego ostatniego są programy komputerowe. Najpierw ludzie piszą je w formacie, który mogą zrozumieć za pomocą języka wysokiego poziomu, analogicznego do języka naturalnego, takiego jak angielski, którego używamy na co dzień. Następnie komputery tłumaczą je do postaci kodu na poziomie maszynowym, który komputery rozumieją.
Parsowanie jest również niezbędne w sytuacjach, w których wymagana jest komunikacja między dwoma różnymi programami - na przykład serializacja i deserializacja klasy.
Do tego momentu poznałeś podstawowe koncepcje parsowania danych. Teraz nadszedł czas, aby zbadać istotne koncepcje związane z parsowaniem danych i sposobem działania parsera.

Wyrażenia regularne to seria znaków, które definiują określony wzorzec. Są one najczęściej używane przez języki wysokiego poziomu i języki skryptowe do sprawdzania poprawności adresu e-mail lub daty urodzenia. Chociaż są one uważane za nieodpowiednie do analizowania danych, nadal mogą być używane do analizowania prostych danych wejściowych. To błędne przekonanie wynika z faktu, że niektórzy programiści używają wyrażeń regularnych do każdego zadania parsowania, nawet jeśli nie powinny one być używane. W takich okolicznościach wynikiem jest seria wyrażeń regularnych, które są ze sobą zhakowane.
Wyrażeń regularnych można używać do analizowania niektórych prostych języków programowania, znanych również jako języki regularne. Nie obejmuje to jednak HTML, który można uznać za prosty język. Wynika to z faktu, że wewnątrz znaczników HTML można napotkać dowolną liczbę dowolnych znaczników. Ponadto, zgodnie z jego gramatyką, ma on rekurencyjne i zagnieżdżone elementy, których nie można zaklasyfikować jako zwykły język. Dlatego nie można ich analizować, bez względu na to, jak sprytny jesteś.
Gramatyka to zestaw reguł, które opisują język pod względem składni. Dotyczy więc tylko składni, a nie semantyki języka. Innymi słowy, gramatyka dotyczy struktury języka, a nie jego znaczenia. Rozważmy poniższy przykład:
HI: "HI"
NAZWA: [a-zA-z] +
Powitanie: IMIĘ
Dwa możliwe wyjścia dla powyższego fragmentu kodu to "HI SARA" lub "HI Coding". Jeśli chodzi o strukturę języka, oba są poprawne. Jednak w drugim wyniku, ponieważ "Coding" nie jest imieniem osoby, jest on niepoprawny semantycznie.
Anatomia gramatyki
Możemy przyjrzeć się anatomii gramatyki za pomocą powszechnie używanych form, takich jak Backus-Naur Form (BNF). Ta forma ma swoje warianty, takie jak Rozszerzona Forma Backus-Naur, która wskazuje na powtórzenia. Innym wariantem BNF jest rozszerzona forma Backus-Naur. Jest on używany do opisywania dwukierunkowych protokołów komunikacyjnych.
Gdy używasz typowej reguły w Backus-Naur Form, wygląda ona następująco:
<symbol> : : _expression_
The <symbol> is nonterminal, which means you can replace it with elements on the right, _expression_. The _expression_ could contain terminal symbols as well as nonterminal symbols.
Możesz teraz zapytać, czym są symbole terminalne? Cóż, są to te, które nie pojawiają się jako symbol w żadnym elemencie gramatyki. Typowym przykładem symbolu terminalnego jest ciąg znaków, taki jak "Program".
Ponieważ reguła taka jak powyższa technicznie definiuje transformację między nieterminalem a grupą nieterminali i terminalem po prawej stronie, można ją nazwać regułą produkcji.
Typ gramatyki
Istnieją dwa rodzaje gramatyk: gramatyka regularna i gramatyka bezkontekstowa. Gramatyki regularne są używane do definiowania wspólnego języka. Istnieje również nowszy typ gramatyki znany jako Parsing Expression Grammar (PEG), reprezentujący języki bezkontekstowe i są one również potężne jako gramatyki bezkontekstowe. W każdym razie różnica między tymi dwoma typami zależy od notacji i sposobu implementacji reguł.
Łatwiejszym sposobem na rozróżnienie dwóch gramatyk jest _expression_, czyli prawa strona reguły może mieć postać :
W rzeczywistości łatwiej to powiedzieć niż zrobić, ponieważ konkretne narzędzie może dopuszczać więcej symboli terminalnych w jednej definicji. Następnie może przekształcić wyrażenie w poprawną serię wyrażeń, która należy do jednego z powyższych przypadków.
Tak więc nawet wulgarne wyrażenie, które napiszesz, zostanie przekształcone w poprawną formę, mimo że nie jest zgodne z językiem naturalnym.

Ponieważ parser jest odpowiedzialny za analizę ciągu symboli w języku programowania zgodnym z regułami gramatyki, które właśnie omówiliśmy, możemy podzielić funkcjonalność parsera na dwuetapowy proces. Zazwyczaj parser otrzymuje polecenie programowego odczytania, przeanalizowania i przekształcenia nieustrukturyzowanych danych do formatu strukturalnego.
Dwa główne komponenty składające się na parser to analiza leksykalna i analiza składniowa. Ponadto niektóre parsery implementują również komponent analizy semantycznej, który pobiera ustrukturyzowane dane i filtruje je jako: pozytywne lub negatywne, kompletne lub niekompletne. Chociaż można założyć, że proces ten dodatkowo usprawnia proces analizy danych, nie zawsze jest to scenariusz.
Analiza semantyczna nie jest wbudowana w większość parserów ze względu na bardziej preferowane praktyki ludzkiej analizy semantycznej. Dlatego analiza semantyczna powinna być dodatkowym krokiem, a jeśli planujesz ją przeprowadzić, musi ona uzupełniać twoje cele biznesowe.
Następnie omówmy dwa główne procesy parsera.
Jest on wykonywany przez Lexar, który jest również nazywany skanerem lub tokenizatorem, a jego rolą jest przekształcenie ciągu surowych nieustrukturyzowanych danych lub znaków w tokeny. Często ten ciąg znaków, który wchodzi do parsera, jest w formacie HTML. Następnie parser tworzy tokeny, wykorzystując jednostki leksykalne, w tym słowa kluczowe, identyfikatory i ograniczniki. Jednocześnie parser ignoruje leksykalnie nieistotne dane, o których wspomnieliśmy w sekcji wprowadzającej. Na przykład obejmują one białe znaki i komentarze wewnątrz dokumentu HTML.
Po tym, jak parser odrzuci nieistotne tokeny podczas procesu leksykalnego, reszta procesu parsowania zajmuje się analizą składniową.
Ta faza parsowania danych polega na skonstruowaniu drzewa parsowania. Oznacza to, że po utworzeniu tokenów parser układa je w drzewo. Podczas tego procesu nieistotne tokeny są również przechwytywane do struktury zagnieżdżania samego drzewa. Nieistotne tokeny obejmują nawiasy, średniki i nawiasy klamrowe.
Aby lepiej to zrozumieć, zilustrujmy to prostym równaniem matematycznym: (a*2)+4
( => nawias
a => Wartość
* => Pomnóż
2 => Wartość
)=> Nawias
+ => Plus
4 => Wartość
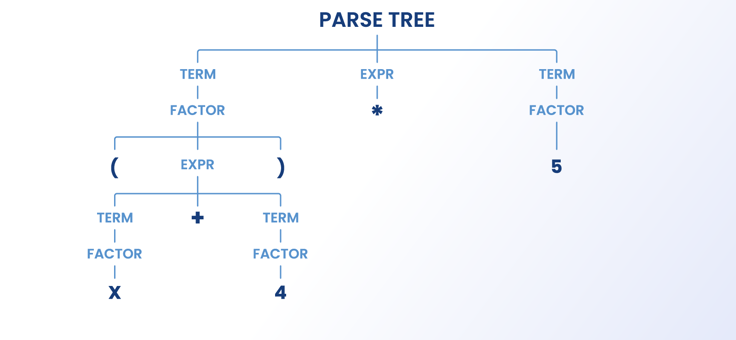
Gdy parser wyodrębnia dane z elementów HTML, postępuje zgodnie z tą samą zasadą.
Zrozumiałeś już podstawowe aspekty parsera. Teraz nadszedł czas na ekscytujący aspekt, czy zbudować własny parser, czy zlecić to na zewnątrz. Najpierw przyjrzyjmy się zaletom i wadom każdej z metod.

Zbudowanie własnego parsera wiąże się z wieloma korzyściami. Jedną z kluczowych korzyści jest większa kontrola nad specyfikacjami. Ponadto, ponieważ parsery nie są ograniczone do jednego formatu danych, masz luksus dostosowania go do różnych formatów danych.
Inne znaczące korzyści obejmują oszczędność kosztów i kontrolę nad aktualizacją i utrzymaniem wbudowanego parsera.
Własny parser nie jest pozbawiony wad. Jedną z istotnych wad jest to, że pochłania on mnóstwo cennego czasu użytkownika, który ma znaczną kontrolę nad jego konserwacją, aktualizacjami i testowaniem. Inną wadą jest to, czy można kupić i zbudować potężny serwer do analizowania wszystkich danych szybciej niż jest to wymagane. Wreszcie, konieczne byłoby przeszkolenie całego personelu wewnętrznego w celu zbudowania parsera i zapewnienia szkoleń w tym zakresie.
Outsourcing parsera pozwala zaoszczędzić pieniądze wydawane na zasoby ludzkie, ponieważ firma kupująca zapewnia wszystkie zadania, w tym serwery i parser. Ponadto prawdopodobieństwo wystąpienia istotnych błędów jest najmniejsze, ponieważ firma, która go stworzyła, z większym prawdopodobieństwem przetestuje wszystkie scenariusze przed wypuszczeniem go na rynek.
Jeśli wystąpi jakikolwiek błąd, firma, od której zakupiono parser, zapewni wsparcie techniczne. Zaoszczędzisz również dużo czasu, ponieważ podejmowanie decyzji dotyczących budowy najlepszego parsera będzie pochodzić z outsourcingu.
Chociaż outsourcing ma wiele zalet, istnieją również jego wady. Główne wady mają postać możliwości dostosowania i kosztów. Ponieważ firma parsująca stworzyła pełną funkcjonalność, wiązałoby się to z większymi kosztami. Ponadto pełna kontrola nad funkcjonalnością parsera byłaby ograniczona.
W tym długim artykule dowiedziałeś się, jak działa parser i ogólnie proces parsowania danych oraz jego podstawy. Parsowanie danych to długi i skomplikowany proces. Kiedy masz szansę doświadczyć parsowania danych w praktyce, jesteś teraz dobrze wyposażony w bogatą wiedzę na temat jego skutecznego przeprowadzania.
Mamy nadzieję, że skutecznie wykorzystasz tę wiedzę.